Designing a Production-Grade Real-Time AI Credit Scoring Platform with Kubernetes, Kafka, and GPU Acceleration
Modern financial systems demand real-time decisioning at scale. Credit scoring, fraud detection, anomaly detection, and risk modeling increasingly rely on streaming AI architectures rather than batch systems.
Pubudu & Hemalee
2/21/20263 min read
A ModNex Engineering Architecture Perspective
Modern financial systems no longer operate in batch cycles. Decisions that once took hours now need to be made in milliseconds. Whether evaluating a loan application, detecting fraud in a transaction, or calculating risk exposure, enterprises increasingly rely on real-time AI-driven decision platforms.
At ModNex, we designed and implemented a production-style streaming AI architecture that demonstrates how modern cloud-native technologies converge to power intelligent decision systems. While our initial implementation was validated in a local lab environment, the architecture itself reflects a scalable, enterprise-ready design that can be deployed across full Kubernetes clusters or Red Hat OpenShift environments.
This article outlines that architecture and the engineering principles behind it.
The Core Problem: Real-Time AI Decisioning
In a credit scoring scenario, the system follows,
Receive loan application data from external channels (web portals, APIs, mobile apps).
Process each application asynchronously.
Invoke an AI model to estimate Probability of Default (PD).
Produce a decision event (approve/reject/risk tier).
Store and forward that decision for downstream systems.
Monitor latency, throughput, and errors continuously.
The architecture ensures,
Horizontally scalable
Fault tolerant
Observable
Secure
GPU-accelerated for performance
Cloud-native and portable
Traditional monolithic systems cannot meet these requirements efficiently. This is where event-driven and containerized AI platforms become essential.
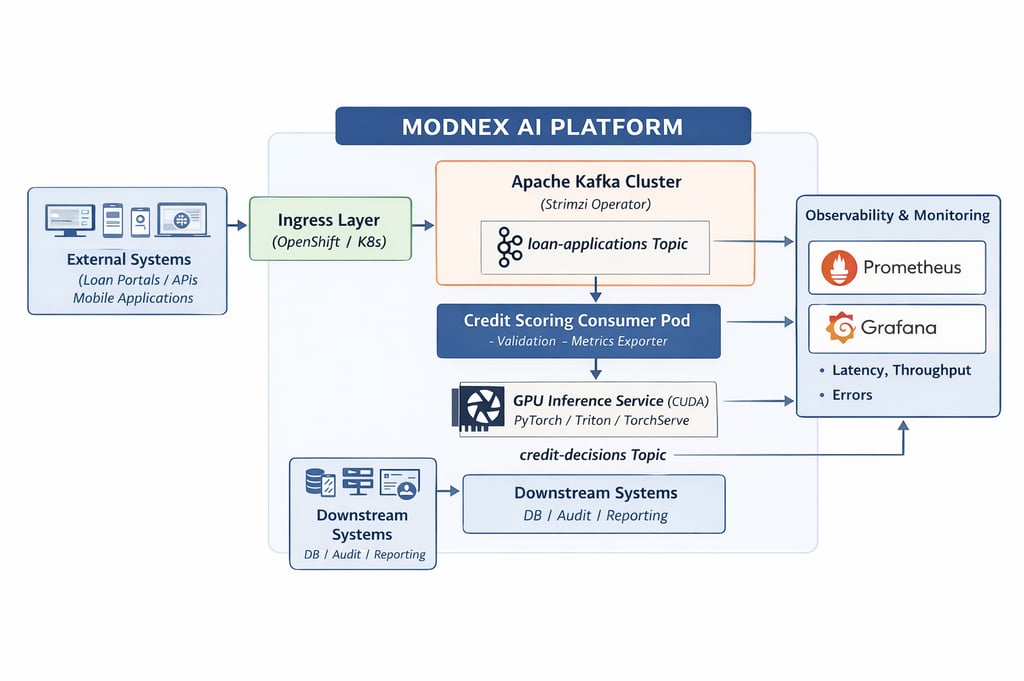
High-Level Production Architecture
At the heart of the ModNex AI platform is an event-driven streaming backbone powered by Apache Kafka.
Client systems publish loan application events into a Kafka topic (loan-applications). These events are processed asynchronously by a Kubernetes-based microservice — the credit scoring consumer. The consumer invokes a GPU-accelerated inference service running PyTorch models over CUDA. Once scored, the decision is written back into Kafka (credit-decisions), where downstream systems can consume it independently.
Parallel to the scoring flow, Prometheus continuously scrapes application metrics, and Grafana provides real-time dashboards for observability.
The architecture separates concerns clearly:
Ingress Layer – Accepts and routes incoming traffic.
Streaming Backbone (Kafka) – Decouples producers and consumers.
AI Scoring Service – Stateless business logic layer.
GPU Inference Engine – High-performance model execution.
Observability Stack – Metrics, monitoring, and alerting.
Downstream Systems – Databases, audit logs, risk engines.
This separation ensures each layer can scale independently and evolve without disrupting the whole system.
Kafka as the Backbone
Kafka enables event-driven decoupling. Instead of synchronously invoking scoring services, applications publish events and move on. Consumers process these events independently.
In production, Kafka provides:
Message durability
Replay capability (critical for audits)
Partitioned scalability
Backpressure management
Horizontal scaling
Using the Strimzi Operator on Kubernetes, Kafka clusters can be declaratively managed, upgraded, and scaled. In production environments, a multi-broker Kafka cluster with replication and TLS encryption ensures resilience and compliance.
The need of GPU-Accelerated Inference
AI models, particularly deep learning models, benefit significantly from GPU acceleration. While small models can run on CPUs, production-scale inference systems handling thousands of requests per second require parallel processing.
In Modnex architecture:
The inference service runs in a CUDA-enabled container.
Kubernetes can schedule workloads onto GPU nodes using the NVIDIA device plugin.
The model executes on the GPU, returning probability scores in milliseconds.
In OpenShift environments, this is further enhanced using the NVIDIA GPU Operator, enabling secure and managed GPU resource allocation.
GPU acceleration reduces inference latency and increases throughput, both critical for financial systems where decision time directly affects user experience and operational efficiency.
Observability: Engineering Beyond Functionality
A production system is incomplete without visibility.
We integrated Prometheus and Grafana to monitor
Application throughput
Inference latency distributions
Error rates
Consumer processing volume
Resource usage
Kafka consumer lag
In enterprise environments, observability extends further
SLA/SLO dashboards
Alertmanager integration
Centralized logging (Loki or Elasticsearch)
Distributed tracing
Observability transforms the system from a black box into an inspectable, measurable platform. This is critical for regulated industries like finance.
Scaling the Architecture in Production
While the initial validation ran in a constrained environment, the architecture is designed for:
Horizontal Pod Autoscaling
AI consumers can scale based on CPU, memory, or Kafka lag metrics.
Kafka Scaling
Partitions and brokers can increase dynamically to handle load spikes.
GPU Node Pools
Dedicated GPU worker nodes can scale independently.
Model Lifecycle Management
Models can be versioned and deployed using MLOps pipelines (e.g., MLflow or CI/CD pipelines).
Canary Deployments
New model versions can be rolled out gradually, validating performance before full promotion.
OpenShift Deployment Model
In a full Red Hat OpenShift environment, the architecture benefits from:
Integrated security policies (SCC)
Route-based ingress
OperatorHub-managed components
Built-in monitoring
Enterprise-grade RBAC
Integrated CI/CD
The same architecture transitions naturally from a lab cluster to production-grade infrastructure.
How this Architecture benefits to Enterprises
Modern financial institutions require,
Real-time decisioning
Regulatory auditability
Resilience under load
AI lifecycle governance
Infrastructure portability
Observability and compliance
This platform addresses those requirements through a modular, cloud-native design that combines streaming systems, AI acceleration, and container orchestration.
It is not merely a machine learning model, it is an AI infrastructure framework.
The Bigger Picture
The convergence of AI, Kubernetes, Kafka, and GPU acceleration defines the next generation of enterprise systems. Traditional application architectures are evolving into intelligent event-driven platforms.
At ModNex, we focus on building scalable AI infrastructures that can move from prototype to production without architectural redesign. The goal is not experimentation, it is operational AI.
In upcoming articles, we will explore:
Model lifecycle automation
Kafka lag-based autoscaling
OpenShift production deployment guides
GPU scheduling strategies
Secure multi-tenant AI clusters
The future of financial systems is real-time, distributed, observable, and intelligent. And this architecture is one step toward that future.